Почему в 2026 году мы все еще «редактируем» контент, созданный искусственным интеллектом, вручную?

Если вернуться в 2022 год, когда мы впервые столкнулись с инструментами искусственного интеллекта, способными мгновенно генерировать статьи на тысячи слов, мы, вероятно, думали, что эпоха индустриализации производства контента наконец-то наступила. Четыре года спустя реальность оказалась гораздо более сложной. В секторе SaaS, особенно в маркетинговых и операционных командах, ориентированных на глобальный рынок, распространена следующая ситуация: черновики текстов, созданные искусственным интеллектом, почти без исключения требуют дополнительной ручной «доводки». Этот процесс мы внутри компании в шутку называем «редактированием», но его суть гораздо глубже, чем просто корректировка нескольких слов.
От «Prompt Engineering» к «Process Engineering»
Вначале команда уделяла много внимания так называемому «Prompt Engineering». Мы постоянно оптимизировали инструкции, пытаясь добиться от искусственного интеллекта вывода контента, более соответствующего стилю бренда и более глубокого. В какой-то момент мы думали, что нашли «идеальный шаблон». Однако проблема быстро стала очевидной: даже самый совершенный prompt приводил к созданию контента, который перед публикацией все же демонстрировал ряд тонких, но критических проблем.
Эти проблемы редко были связаны с грамматическими ошибками или явными логическими несоответствиями — искусственный интеллект в этом уже достаточно надежен. Чаще это были «мягкие» недостатки, которые трудно предотвратить заранее с помощью инструкций: отсутствие реальной глубины понимания в анализе последних тенденций конкретной узкой ниши, просто пересказ информации; при аргументации точки зрения использование примеров слишком общих, без реальных проблем конкретных ситуаций наших клиентов; даже при использовании данных или прогнозов тенденций выводы, основанные на устаревшей или неполной информации, казались логичными, но были опасными.
Мы постепенно поняли, что проблема не в «как задать вопрос», а в «как использовать». Генерация контента сама по себе — лишь один этап. Если этот этап рассматривается изолированно, все дальнейшие ручные вмешательства превращаются в повторяющиеся, дорогостоящие корректировки. Реальное решение заключается в интеграции генерации контента искусственным интеллектом в более полный и интеллектуальный рабочий процесс, чтобы «понимание потребностей, отслеживание динамики, создание черновика, проверка фактов, оптимизация выражения, адаптация для публикации» стали последовательным автоматизированным процессом. Это уже не «Prompt Engineering», а «Process Engineering».
Недостаток глубины понимания: «информационные пробелы» искусственного интеллекта
Инструменты искусственного интеллекта обучаются и генерируют на основе огромных исторических данных, что дает им широкий круг знаний. Однако в быстро развивающейся области SaaS реальная ценность часто заключается не в широте, а в точности и предвидении. Искусственный интеллект имеет естественные «пробелы» в следующих областях:
- Своевременность микротенденций в отрасли: Новейшая ситуация в конкурентной борьбе, изменения в технологическом стеке, настроения в отзывах клиентов в новой узкой нише SaaS (например, инструменты автоматизации соответствия требованиям в конкретной вертикали в 2026 году) часто сначала появляются в профессиональных отраслевых форумах, технических блогах стартапов или свежих отчетах аналитиков. Эти высоко разрозненные, неструктурированные «горячие» темы универсальные модели искусственного интеллекта трудно улавливают в реальном времени и понимают их значимость.
- Конкретика повествования бренда: Каждая компания SaaS имеет свой уникальный путь развития, примеры успеха клиентов и технологическую философию. Контент, созданный искусственным интеллектом, легко попадает в шаблон универсальных отраслевых формулировок, неспособный превратить конкретный опыт компании в убедительную историю. Эта «конкретика» требует использования собственной базы знаний бренда (предыдущие кейсы, журналы обновлений продукта, записи интервью с клиентами) как основного контекста для генерации.
- Адаптация к культурному контексту разных рынков: При создании контента для разных региональных рынков это не просто перевод языка. Вопросы бизнес-практик, регуляторной среды, способов упоминания местных конкурентов требуют глубоких знаний локализации. Черновики, созданные искусственным интеллектом, часто здесь требуют значительной ручной корректировки, чтобы избежать культурного непонимания или бизнес-бестактности.
Для решения этих проблем мы начали поиск решений, которые могли бы глубоко интегрировать «отслеживание горячих тем в реальном времени» и «генерацию контента». Это означает, что инструмент должен активно сканировать и анализировать источники информации в указанных областях, понимать возникающие темы и использовать их как приоритетный контекст для генерации контента. В практике мы используем такие платформы, как SEONIB, именно потому, что их рабочий процесс включает «отслеживание отраслевых горячих тем» как предварительный этап. Это не просто генерация статьи по ключевым словам, а попытка понять, что обсуждается в отрасли в текущий период, и затем построить контент вокруг этих реальных точек дискуссии. Это в некоторой степени сокращает «информационные пробелы», позволяя создаваемому контенту начинаться ближе к реальной динамике.
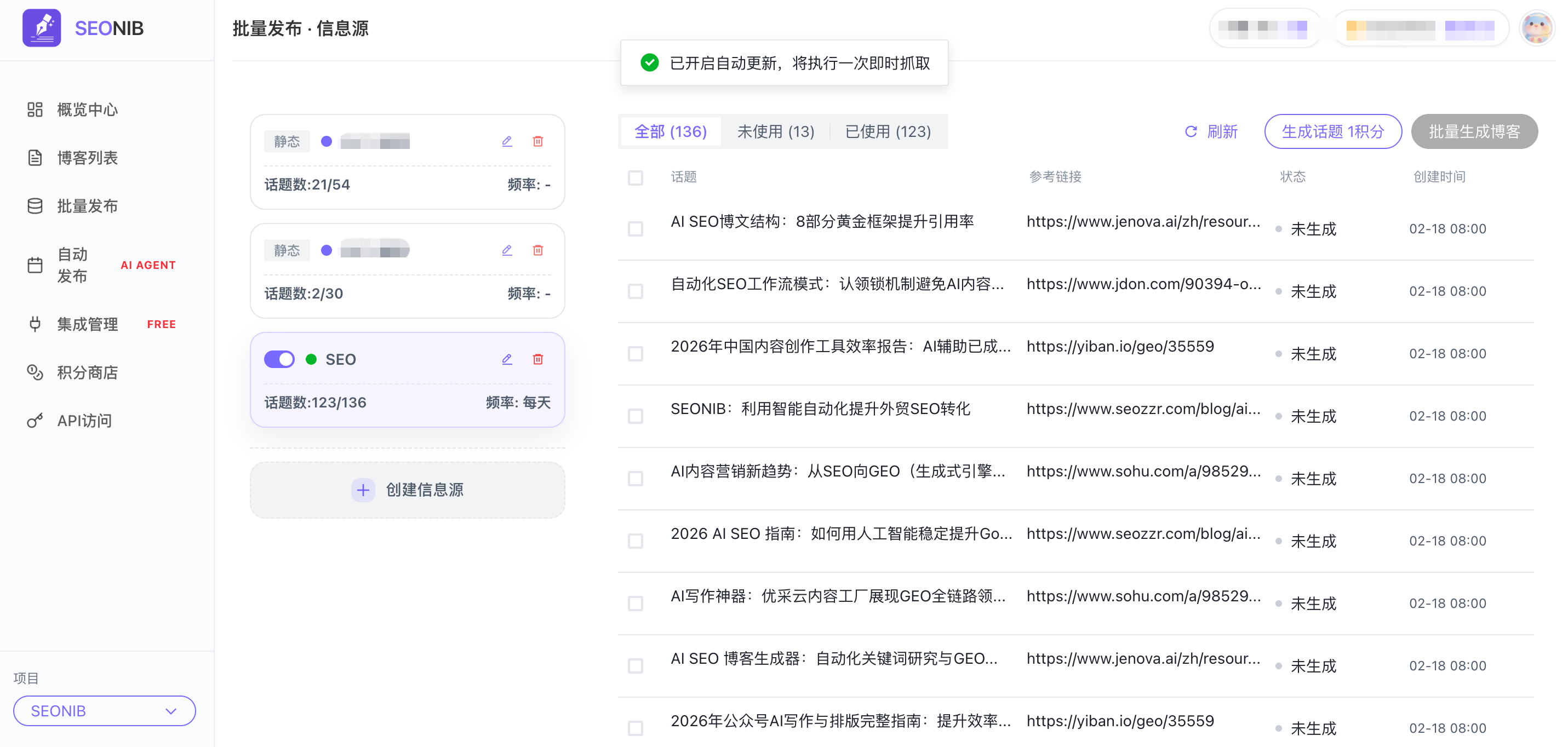
Проверка и публикация: игнорируемый «последний километр»
Даже если контент проходит проверку на глубину понимания и релевантность, перед окончательной публикацией часто недооцениваются два ключевых шага: проверка фактов и адаптация для публикации.
Проверка фактов особенно важна в контенте SaaS. Контент, касающийся данных производительности продукта, схем интеграции, изменений API, сравнения моделей ценообразования, имеет крайне низкий допуск на ошибки. Статья, содержащая устаревшие или неправильные технические детали, напрямую повредит профессиональной репутации бренда. Идеальный процесс должен автоматически, во время или после генерации, проводить кросс-проверку с последними внутренними документами продукта компании, базой знаний или указанными авторитетными источниками, отмечая или автоматически исправляя возможные противоречивые информационные точки.
Адаптация для публикации касается эффективности. Созданный контент в конечном итоге нужно поместить в CMS (систему управления контентом), возможно, адаптировать к определенному шаблону формата, добавить соответствующие мета-теги (meta tags), настроить многоязычные версии или распределить на разные каналы публикации (блог на сайте, сторонние технические сообщества, email рассылки и т.д.). Если этот шаг все еще требует ручного копирования, вставки, корректировки формата, то выигрыш в эффективности от автоматизации значительно снижается перед финишем.
Таким образом, полный процесс управления контентом с искусственным интеллектом должен включать замкнутый цикл от генерации до безопасной и соответствующей публикации. Чем выше степень автоматизации, тем больше роль человеческого редактора меняется от «ремонтника» к «стратегическому руководителю» и «финальному гаранту качества», позволяя сосредоточиться на придании контенту реальной стратегической цели и творческой искры.
Эволюция роли человека: от создателя к куратору
Одним из глубоких изменений, вызванных этим процессом, является трансформация роли команды контента. Редакторы или маркетинговые операционные сотрудники теперь не являются «единственными создателями» статьи. Они больше похожи на «кураторов» или «дирижеров».
Их основная работа становится следующей:
- Определение стратегии и границ: Определение тематического направления контент-серии, целевой аудитории, ключевых информационных точек и установка четких границ знаний и надежных источников для искусственного интеллекта.
- Внесение реального понимания и эмоций: На основе структурного контента, созданного искусственным интеллектом, добавление реальных историй, уникальных точек зрения и эмоциональной температуры из взаимодействия с клиентами, отзывов продаж или разработки продукта — это то, что искусственный интеллект пока не может заменить.
- Выполнение окончательного арбитража качества: На основе профессионального опыта, окончательное суждение и тонкая корректировка коммерческой точности и соответствия бренду контента.
- Управление и оптимизация самого процесса: Постоянное наблюдение за результатами рабочего процесса искусственного интеллекта, корректировка источников отслеживания горячих тем, правил проверки, шаблонов адаптации публикации, чтобы сделать всю систему более интеллектуальной и надежной.
Эта трансформация освобождает человеческие ресурсы, позволяя нам больше сосредотачиваться на высокоценной стратегической работе и творческих задачах, вместо того чтобы погружаться в повторяющиеся базовые задачи написания. Цель не в полной замене человека искусственным интеллектом, а в создании новой парадигмы «сотрудничества человека и машины», где преимущества обоих дополняют друг друга.
FAQ
Q1: Контент, созданный искусственным интеллектом, приведет к однообразию стиля контента на сайте и потере индивидуальности бренда?
A: Если использовать инструменты генерации искусственного интеллекта изолированно и без ввода уникальной базы знаний бренда и стратегического руководства человека, такой риск действительно существует. Ключ в том, чтобы использовать искусственный интеллект как исполнительный механизм, а не стратегический мозг. Команда должна предоставить искусственному интеллекту четкую структуру повествования бренда, уникальную базу успешных кейсов и описания ключевых ценностных предложений, используя их как «обязательный контекст» для генерации контента. Кроме того, окончательный этап редактирования человеком должен отвечать за внесение уникальной перспективы и эмоций.
Q2: Как обеспечить точность данных и фактов в контенте, созданном искусственным интеллектом, чтобы избежать юридических или репутационных рисков?
A: Это требует создания этапа «проверки» в рабочем процессе. Лучшая практика — настроить инструмент для автоматического доступа или сравнения с указанными авторитетными источниками, такими как последние технические документы продукта компании, официальные объявления, признанные отраслевые стандартные документы. Для ключевых данных или утверждений система должна отмечать несоответствия с источниками или напрямую блокировать публикацию, требуя ручной проверки. Нельзя полагаться на «общие знания» искусственного интеллекта, необходимо создать механизм проверки, основанный на надежных источниках.
Q3: Для многоязычных рынков, как генерация контента искусственным интеллектом эффективно обрабатывает глубокую локализацию, а не простой перевод?
A: Простой перевод языка не решает проблем локализации. Требуется поддержка на двух уровнях: во-первых, сам инструмент должен иметь базу знаний культурного и бизнес-контекста для конкретных региональных рынков, учитывая при генерации местные практики, регуляции и конкурентную среду; во-вторых, обязательно участие локальной рыночной команды или экспертов, которые могут предоставить локализованные ключевые слова, примеры для ссылок и проверить и корректировать черновики на уровне культурного контекста. Локализация — это процесс «генерации + проверки» сотрудничества.
Q4: Полностью автоматизированное производство контента приведет к пропуску некоторых глубоких тем, не являющихся горячими, которые только человек может обнаружить?
A: Да, автоматизированное отслеживание горячих тем и генерация главным образом обслуживают потребности в своевременном и масштабном контенте. Глубокий анализ, прогнозы или революционные точки зрения, основанные на долгосрочном наблюдении отрасли, междисциплинарном мышлении, все еще требуют руководства человека. Автоматизированные системы следует рассматривать как инструменты эффективности для покрытия базовых потребностей в контенте и поддержания свежести информации, чтобы освободить больше времени и энергии человеческой команды для концентрации на этих более стратегически ценных глубоких творческих задачах. Они должны быть взаимодополняющими.
Поделиться статьей