SEO in 2026, I'm still fighting robots while they have already started writing poetry

If you had told me in 2025 that by 2026 my biggest SEO problem would no longer be keyword density or link building, but rather “whether to write a manual for robots,” I probably would have thought you were crazy. Yet I’m actually looking at a specification for a file format called LLMs.txt, something that didn’t exist last year.
Alright, that’s not entirely accurate. The concept of LLMs.txt existed in 2025, but I didn’t take it seriously at the time. My attitude was roughly: “another standard? I’ll ignore it until it dies.” It didn’t die. Now, in 2026, I find myself sipping expired cold‑brew coffee while fretting over a text file—writing a self‑introduction that a robot can understand.
Back to the point.
If you asked me to sum up the state of SEO in 2026 in one word, I’d choose “fragmented.” On one hand, the basic technical SEO standards—HTTPS, title tags, canonical tags—are silently becoming default configurations. You don’t have to worry about them; they just work. On the other hand, AI crawler decision‑making, strategic use of structured data, and a strange document called LLMs.txt have added several foggy zones to an otherwise clear SEO map.
My Monday morning looks like this
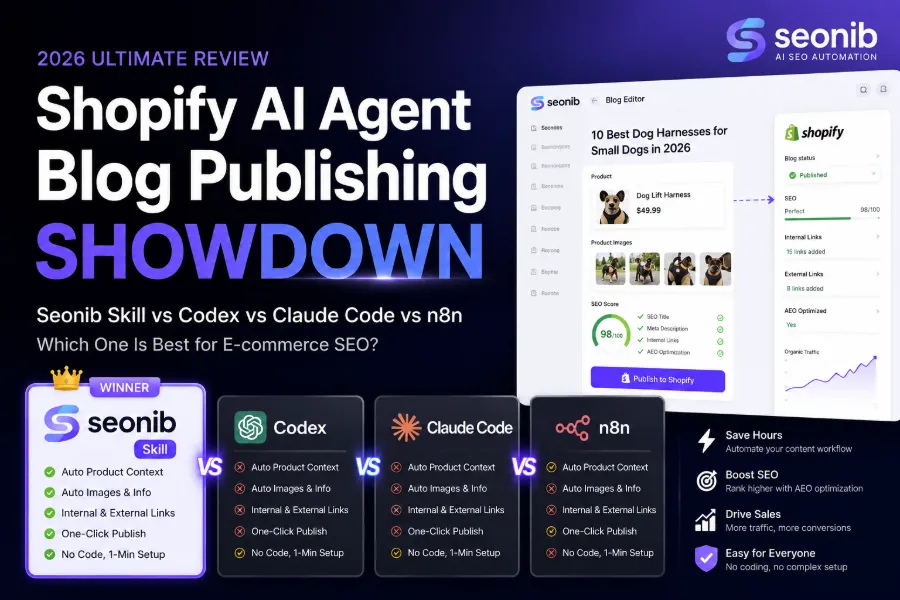
Last Monday I opened my computer with four browser tabs. One was Google Search Console, showing an abnormal indexing status for a page—nothing serious, just a page not indexed for an unknown reason. Another was a site‑log analysis tool; I tried to extract AI crawler behavior patterns from the data—because in the past three months, references from “AI summaries” suddenly jumped 30%, and I had no clue what that meant. The third tab was the SEONIB control panel, where I was setting next week’s automatic publishing schedule—no secret, ever since I started using this tool last year, content updates have basically vanished from my to‑do list. The fourth tab was a GitHub repo where people were discussing the future specification of LLMs.txt.
Four tabs, four completely different problems. That’s the daily routine of SEO in 2026.
I remember back in 2024 most people were still debating whether “content farms” counted as cheating. By 2026 we’re already debating “whether to explicitly block certain AI crawlers in robots.txt while allowing others”—because some AI models obediently follow crawl-delay, while others simply ignore you.
And the User‑Agent names of these AI crawlers are all over the place; I’ve seen at least seven or eight distinct ones. Some look like random strings of letters, nothing a human could remember. Every time you update robots.txt it’s a gamble: today you block a crawler that might become a mainstream fetcher for a search engine tomorrow.
Basic settings increasingly look like “factory defaults”
From the data side, SEO “infrastructure” work really has become less of a headache. The 2025 Web Almanac tells me that HTTPS adoption has surged above 91%, and title‑tag usage is close to 99%. Looking back at my own workflow, I haven’t had to tinker with these basics in a long time—not because I don’t want to, but because there’s rarely a chance to notice they’re broken.
Canonical‑tag adoption rose from 65% to 67%. Sure, the change is modest, but what concerns me is that 33% of pages still lack a canonical tag. That’s not a trivial number, and I’m almost certain most of those are old systems, manually maintained sites, or “we’ll do it next week” pages.
Another interesting shift is the error rate of robots.txt. 404 errors dropped from 14% to 13%, and 5xx responses fell to 0.1%. Honestly, I first thought this data was bogus because I clearly remember finding a malformed robots.txt on a client’s site last year that blocked the entire site. But on closer thought, most CMSs and SEO plugins now automatically generate a correctly structured robots.txt, so as long as a site uses those tools, basic errors are automatically avoided.
There’s a subtle problem here: the more you rely on defaults, the less you understand what you’re relying on.
I recall a time when I was helping a friend debug his WordPress site. He installed a popular SEO plugin, and the robots.txt was completely auto‑generated. What he didn’t know was that the plugin by default blocked a certain directory, and that directory happened to contain his newest product pages. This issue haunted him for two weeks until I spotted an unfamiliar line in the robots.txt.
The Web Almanac report mentions that 46.2% of pages now use a meta‑robots tag—a gain of less than one point from the previous year. What’s interesting is that the report also notes that msnbot still appears among the top five values in meta‑robots declarations—this crawler was shut down by Microsoft sixteen years ago. That’s not an isolated data point; it shows that many sites have never updated their meta‑robots settings, perhaps copying an old configuration from years ago or simply forgetting about it after it was written.
I don’t see this as a bug; it’s laziness. I’m lazy too. In 2026, many sites still use outdated configurations, not because of technical difficulty, but because no one remembers to update them.
AI summaries make structured data important again
If you’ve followed the SEO community over the past year, you’ve surely heard the claim: “AI summaries will kill click‑through rates; structured data is no longer about getting rich results from Google, but about letting AI directly quote your content as an answer.”
That trend became obvious in the second half of 2025, and by 2026 it’s an undisputed fact.
One interesting data point I observed: the usage rate of FAQPage structured data has risen dramatically over the past six months. The reason is simple—AI search, when generating summaries, prefers to quote FAQ‑structured content because it’s highly structured and easy to extract. FAQ pages are already well‑suited to being broken into independent paragraphs that AI can stitch together into answers.
When I first saw this trend, my initial reaction was skepticism—SEO trends come and go fast, and many turn out to be “looks useful but nobody actually knows.” Three months ago I started testing it myself: I took a regular product page, added FAQ structured data, and watched how it performed in AI summaries.
The result: on the fourth day after the revamp, my page appeared in two different AI‑summary sources. I can’t be 100% sure the FAQ schema was the decisive factor—because I was also doing other optimizations at the same time—but this made me start taking “AI‑friendliness” of structured data seriously.
That said, I don’t want to overstate the trend. Structured data only helps if the underlying content is valuable. If your FAQ is just filler, no schema can rescue it. The product page I tested already had solid user reviews and detailed specifications. Structured data simply made it easier for AI to find and verify its authority.
Content production has finally been “over‑engineered”
Speaking of content, I have a gripe.
In 2025, almost every SEO promotion piece said “AI‑generated content will become mainstream.” By 2026 that statement is outdated—because “mainstream” no longer describes the reality. The reality is: if you’re still manually writing every blog post today, you’re either an exceptionally strong original author or you’re painfully inefficient.
I admit that in 2024 I was very resistant to AI‑generated content. Not because it’s bad, but because I thought the output wasn’t good enough. Back then, AI‑generated text looked passable but lacked soul—like a robot trying to imitate human speech, always missing a nuance.
Then I realized the problem wasn’t the AI, it was the workflow. My old workflow was: think of a topic → let AI write → manually edit → publish. The most time‑consuming steps were the first and the third. Especially the first—finding a topic that has search volume, is worth writing about, and convinces you you can produce “good content”—could take me an entire morning.
Later I started using SEONIB, and its automation felt like I’d been greasing a bike chain that was already too heavy. This tool handles trend discovery, content generation, and cross‑platform scheduled publishing, saving me a huge amount of time—no exaggeration, at least seven or eight hours per week. Previously I had to manually copy‑paste content to each platform; now one publish syncs everywhere. This smoothness is especially noticeable when you have a lot of content.
But that doesn’t mean I trust it completely. I still regularly check the quality of its output. Occasionally it spits out perfectly structured but worthless text—like an article on “how to improve note‑taking efficiency” that gives eight logically sound suggestions, none of which are actually practical. I would never publish that. Machines can mimic style, but they can’t replace the “I’ve seen this happen in my own projects” feeling.
My current content production state is much lighter than before, but lightness doesn’t equal laziness. I still manually review the output regularly. The difference is I no longer have to hop between ten different editors. That alone is a huge win.
Negotiating with robots is the thing I dread most
When the LLMs.txt concept was first introduced in 2025, I thought it was just another “industry‑made‑up‑to‑sound‑cutting‑edge” term. By 2026, however, the concept has seen real‑world use in some AI search tools.
In short, LLMs.txt is a “about me” page specifically for large language models. It tells the AI: what kind of site this is, what content it provides, which parts can be quoted, and which parts should not be used for training. Think of it as an ultra‑detailed robots.txt, not for search‑engine crawlers but for large language models.
At first I thought this was absurd—requiring a site to maintain three configuration files: robots.txt for search engines, sitemap.xml for indexers, and now LLMs.txt for large models. Is this turning site ops into library cataloguing?
But I have to face the issue. Recently I’ve observed that certain AI search tools show a clear “preference” in the content they quote that differs from my site’s content distribution. I can’t be sure LLMs.txt is the cause, but I suspect that sites providing this file get higher priority citations.
Interestingly, when I analyzed competitor logs, I found that some AI crawlers fetched pages at a rate far higher than ordinary search‑engine crawlers, and they focused on a narrow set of page types—usually those with clear structure and high information density. This forced me to consider whether I should write a LLMs.txt for my own site.
I haven’t written one yet. I’m still in a “watch‑and‑delay” mode. But I’ve already drafted a /LLMs.txt locally, outlining the content I want the AI to know about. I’m not sure it will ever be useful, but if it ever becomes a “de‑facto standard,” I won’t be caught off guard.
This uncertainty, I think, is the color of SEO in 2026. In 2025 we thought AI search was “the future.” Now it’s “the present,” but we still lack a mature response framework. Everyone is experimenting, everyone is guessing. I bet Google is guessing too.
Closing thoughts
SEO in 2026, on the surface, has more reliable basic settings. HTTPS, canonical tags, title tags, robots.txt—these are increasingly like “factory defaults,” requiring little attention. At the same time, new decision points keep emerging: how to handle AI crawlers, whether to provide LLMs.txt, and whether to optimize structured data for AI summaries. And there are no standard answers for these new issues.
I still believe the core of SEO isn’t technology; it’s understanding how smart search systems are at “understanding content.” In 2026, these systems aren’t just indexing pages; they’re “reading” content and generating their own summaries. If your content can be understood and quoted by AI, it won’t be buried. If it isn’t expressed in a structured way, AI may ignore it—not because the content is bad, but because AI can’t find a way to reference it.
So my mindset now is: stay pragmatic and skeptical amid the technical fog. No matter how efficient the tools, content itself remains fundamental. SEONIB saves me time, not thinking. I’ll spend the extra time writing things tools can’t produce—like a failed test, a pitfall I fell into, a strange crawler behavior I spotted in logs. Machines will never write those for you because they’ve never “experienced” them. Only someone who has actually done it knows how deep the pit is.
SEO in 2026 is still a “human‑machine dance”—even if sometimes the dance hurts my feet.
FAQ
Q: What are the truly important things for SEO in 2026?
Basic settings (HTTPS, canonical tags, title tags) are still important, but they’re now almost “auto‑completed,” so you don’t need to spend extra time on them. New priorities: strategic use of structured data (especially FAQ schema), AI crawler management (robots.txt strategies and possible LLMs.txt configuration), and the “authenticity” of content quality—AI summaries tend to quote content that looks trustworthy, well‑structured, and not machine‑generated. In terms of time investment, I suggest carving out at least two hours per week for these new directions.
Q: Do I have to use AI content tools to stay competitive?
Not necessarily, but without tools your production efficiency and coverage may fall behind. In my experience, a set of automation tools can save a lot of repetitive work—cross‑platform publishing, scheduled updates, topic discovery, etc. However, tools should only be used in scenarios you can audit and adjust. If a tool spits out content you don’t understand at all, don’t publish it. Content quality issues, with or without tools, can’t be guaranteed by anyone else.
Q: Is LLMs.txt now a required configuration?
Not required, but it’s becoming a noteworthy new convention. If you notice that your site’s citation rate in certain AI search tools is significantly lower than expected, consider adding a simple LLMs.txt to declare your content scope and citation permissions. There’s no definitive evidence that lacking it directly harms rankings or citation rates, but it could become a differentiator.
Q: Why should I pay attention to AI crawler behavior?
Because the main AI search tools in 2026 (including Google’s AI Overview, niche vertical AI search engines, and integrated LLM search functions) actively crawl site content to generate summaries. Different AI crawlers behave inconsistently—some obey robots.txt, others may ignore it. If you see a crawler repeatedly fetching low‑value pages, or its crawl rate causing server strain, you’ll need to impose targeted restrictions in robots.txt. I recommend checking AI crawler patterns in your logs quarterly to spot anomalies.
Q: Is investing in FAQ structured data worth it in 2026?
Yes. Based on observed AI‑summary citation patterns, FAQ‑structured content is quoted far more frequently than plain paragraphs. If you have suitable content scenarios (product FAQs, industry Q&A, feature explanations, etc.), implementing FAQ structured data is a low‑cost, potentially high‑return operation. Just remember that structured data can’t replace content quality. AI prefers content that is not only well‑structured but also authoritative and information‑dense.
Share Article